
What a way to round out the year, adding an incredible 4 percentage points to Alan’s conservative AGI countdown all by itself:
https://lifearchitect.ai/agi/
https://lifearchitect.ai/o3/#smarts
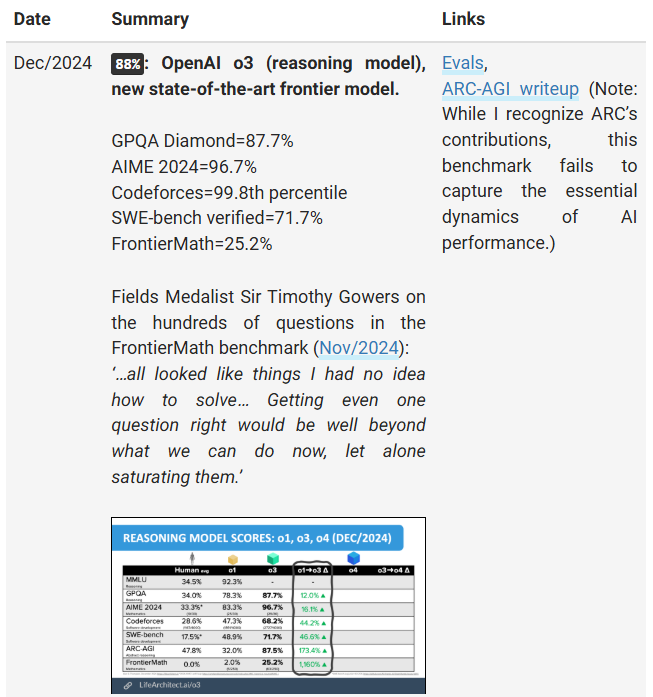
Simply incredible.
Open AI’s o3 model solved 25% of the problems on the frontier math benchmark. [To score 25.2%, o3 must have got at least 63 of 250 questions correct]. It consists of research level mathematics problems. The problems in FrontierMath demand theoretical understanding, creative insight, and specialized expertise, often requiring multiple hours of effort from expert mathematicians to solve. this is what the best mathematicians have to say:
“These are extremely challenging. I think that in the near term basically the only way to solve them, short of having a real domain expert in the area, is by a combination of a semi-expert like a graduate student in a related field, maybe paired with some combination of a modern AI and lots of other algebra packages…” —Terence Tao, Fields Medal (2006)
“[The questions I looked at] were all not really in my area and all looked like things I had no idea how to solve. Getting even one question right would be well beyond what we can do now, let alone saturating them…they appear to be at a different level of difficulty from IMO problems.”
— Timothy Gowers, Fields Medal (2006)
The above demonstrates Open AI’s growing ability to tackle problems requiring reasoning rather than just pattern recognition.Indicates a combination of computational brute force and emergent problem-solving skills within the model. It also suggests potential for AI to become a significant collaborator in mathematical research.
Open AI has not announced when o4 could be expected, but the rumors I’ve seen are that we’re looking at a matter of a few months, rather than a year.
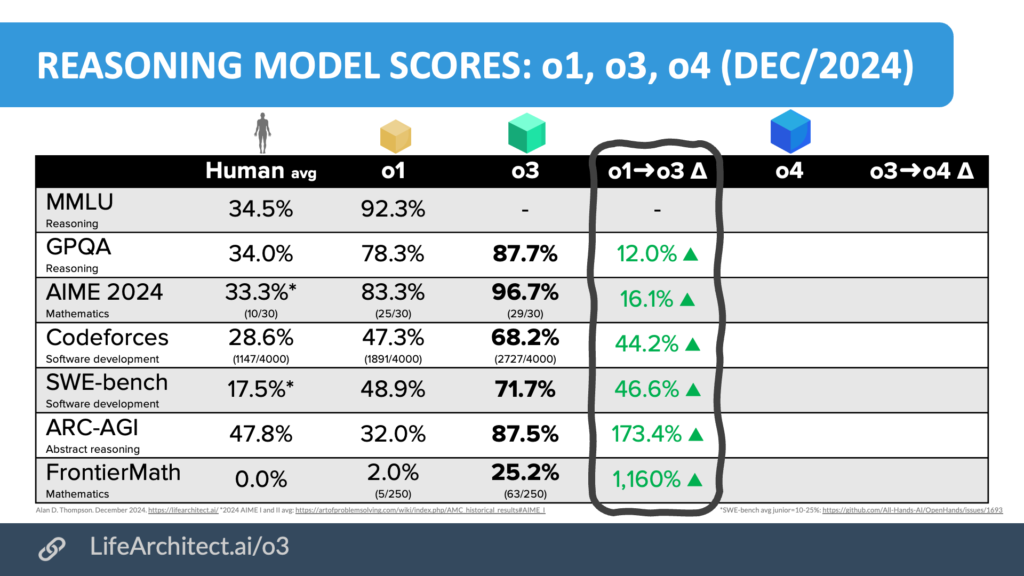
Here’s a quick explanation of what each of these benchmarks is measuring.
1. MMLU (Reasoning)
- What it is: MMLU is a big test that spans dozens of subjects (like history, physics, economics, etc.). It’s often used to check how well AI models handle a wide range of knowledge and reasoning questions—stuff that’s more academic and fact-based.
- Progress (o1 → o3): For MMLU, it shows o1 at 92.3% and no data for o3 (the table has “–” for those columns). So, we don’t have the improvement numbers here, but you can see how high o1 already scored compared to the human average of 34.5%. Humans aren’t built to ace random, wide-ranging, detail-heavy quizzes like MMLU. While individuals can shine in their areas of expertise, they can’t match AI’s vast memory and multitasking ability. It’s less about humans being “bad” and more about the test being optimized for AI’s strengths.
2. GPQA (Reasoning)
- What it is: GPQA is a reasoning benchmark that tests an AI’s ability to understand and answer questions in a general-purpose setting. Think of it like a quiz that checks if the model “gets” the question and can produce logical answers.
- Progress (o1 → o3):
- o1: 78.3%
- o3: 87.7%
- That’s a 12.0% boost, which is quite solid.
3. AIME 2024 (Mathematics)
- What it is: AIME (American Invitational Mathematics Examination) is a high-level math competition. Scoring well on AIME-style questions means the model can handle some tricky math and algebra.
- Progress (o1 → o3):
- o1: 83.3%
- o3: 96.7%
- That’s a 16.1% jump in performance. Pretty impressive, especially for advanced math.
4. Codeforces (Software Development)
- What it is: Codeforces is an online platform where programmers compete by solving coding and algorithmic challenges. This benchmark tests whether the AI can effectively solve programming tasks and logic puzzles.
- Progress (o1 → o3):
- o1: 47.3%
- o3: 68.2%
- That’s a 44.2% improvement. A nice leap in coding and problem-solving skills.
5. SWE-bench (Software Development)
- What it is: SWE-bench (Software Engineering benchmark) checks how well the model can do tasks that software engineers typically deal with, like debugging, code synthesis, or architecture decisions.
- Progress (o1 → o3):
- o1: 48.9%
- o3: 71.7%
- That’s a 46.6% boost. Another big jump in programming competence.
6. ARC-AGI (Abstract Reasoning)
- What it is: ARC (Abstraction and Reasoning Corpus) is a puzzle-based test that measures an AI’s ability to spot visual or pattern-based logic—kind of like an IQ test for machines, where you look at shapes, transformations, and figure out the “rule.”
- Progress (o1 → o3):
- o1: 32.0%
- o3: 87.5%
- That’s a 173.4% rise! Huge jump in abstract puzzle-solving.
7. FrontierMath (Mathematics)
- What it is: FrontierMath likely involves extremely advanced or cutting-edge math tasks—problems that are way beyond basic algebra or geometry, testing the model’s deeper or more creative mathematical reasoning.
- Progress (o1 → o3):
- o1: 2.0%
- o3: 25.2%
- That’s an 1,160% improvement (!). Even though it started near zero, going to over 25% is a dramatic gain.
Bottom line
Each of these rows represents a different skill area—some are purely reasoning or knowledge-based, others are heavy math, and others revolve around coding or abstract logic. You can see the big leaps between o1 and o3—some improvements are modest (like +12% for GPQA), while others are massive (like ARC-AGI’s +173% or FrontierMath’s +1,160%). This table basically shows that the “o3” model has gotten a lot better in solving a wide range of tasks compared to “o1,” especially in tougher challenges like complex math and abstract puzzles.